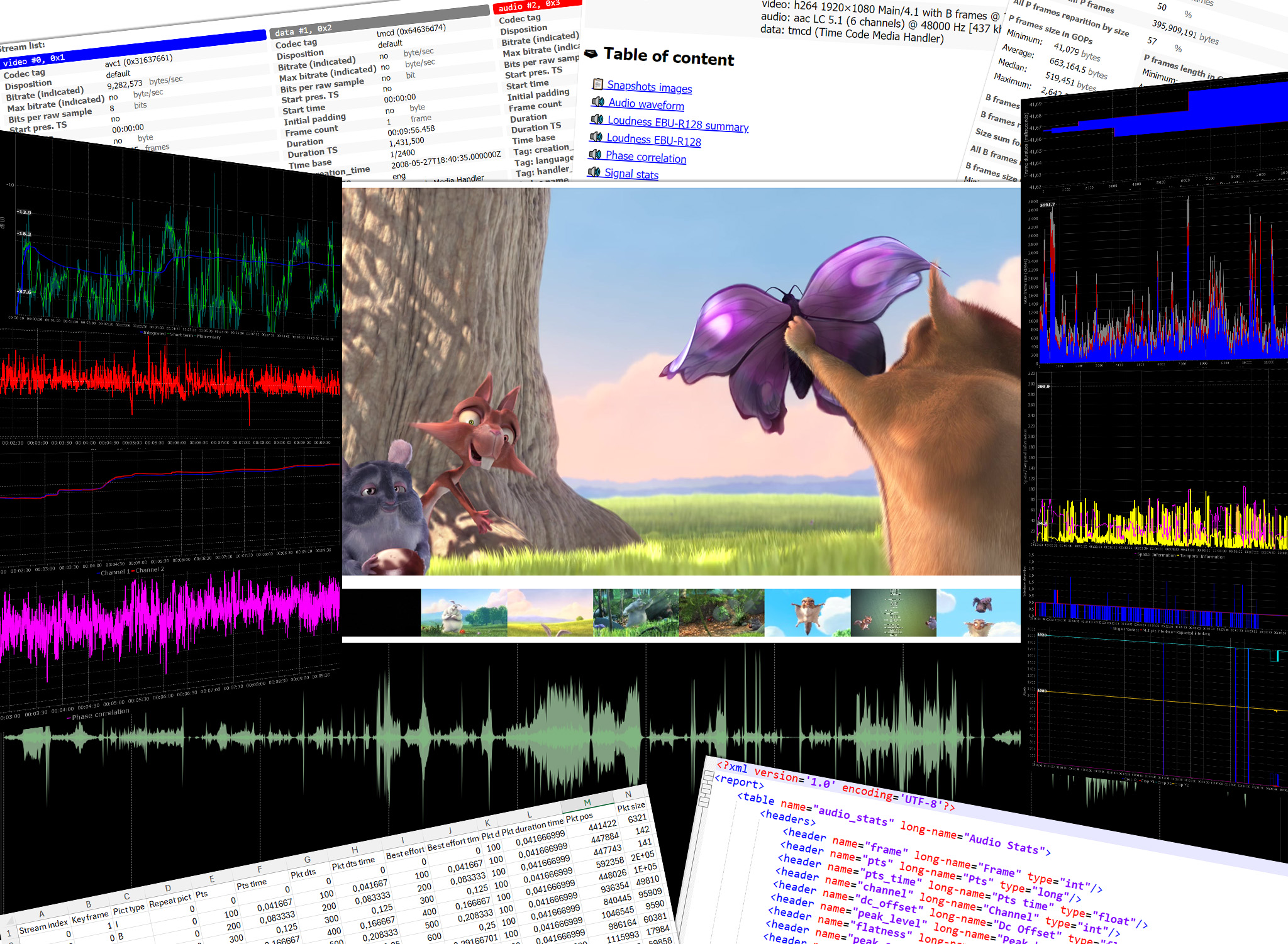
Features
Mediadeepa can handle any audio/video files managed by FFmpeg, and produce reports with it.
Analysis scope is currently based on FFmpeg filters and tools:
- Audio phase meter
aphasemeter - Time domain statistics about audio frames
astats - Audio loudness meter (EBU R128 scanner)
ebur128 - Audio silence detection
silencedetect - Video black/block artifacts/blurred/duplicate/interlacing frames detection (
blackdetect/blockdetect/blurdetect/freezedetect/idet) - Video border detection
cropdetect - Video spatial information (SI) and temporal information (TI)
siti - Structural media container information: audio/video stream frames size, timing, GOP type
- Create a technical resumed of media file based on FFprobe media file header
- Optional filter use, based on command line (user choice) and current FFmpeg filter availability on app environment.
- User can optionally add timed constraints:
- start position on media file
- limit analysis duration on media file
- limit time to do the analysis operation
- During the analyzing operation, an ETA/progress bar is displayed, and based on current FFmpeg processing
And it can export to file the FFprobe XML with media headers (container and A/V streams).
This application can run on three different "modes":
- Process to export: this is the classical mode. Mediadeepa will drive FFmpeg to produce analysis data from your source file, and export the result a the end.
- Process to extract: sometimes, you don't need to process data during the analysis session. So, Mediadeepa can just extract to raw text/xml files (zipped in one archive file) all the gathered data from FFmpeg.
- Import to export: to load in Mediadeepa all gathered raw data files. Mediadeepa is very tolerant with the zip content, notably if they were not created by Mediadeepa (originally). No one is mandatory in zip.
You can process multiple files and directory scans in one run, as well as load a text file as file list to process.
Known limitations for Mediadeepa
- It only support the first video, and the first founded audio stream of a file.
- Audio mono and stereo only.
- Some process take (long) time to do, like SITI and container analyzing, caused by poor FFmpeg/FFprobe performances with these filters.
- Loudness EBU R-128,and audio stats measures works correctly with FFmpeg v7+, due to internal bugs/limitations with the previous versions.
- Limited file start position time and duration are only applied on media analyzing, not container, image snapshot or audio signal.
An internal warning will by displayed if you try to works with a Zip archive created by a different Mediadeepa version.
Current available export formats
With the integrated help, you can get the export features currently available, to use with -f:
txt: Values separated by tabs in text filescsv: Classic CSV files comma separated, "." decimal separatorcsvfr: French flavor CSV files semicolon separated, "," decimal separatorxml: XML Documentjson: JSON Documentxlsx: XLSX Spreadsheet simple raw data export, one tabs by export resultsqlite: SQLite databasegraphic: Data graphical representation audio Loudness (integrated, short-term, momentary, true-peak), audio phase correlation (+/- 180°), audio DC offset, signal entropy, flatness, noise floor, peak level, silence/mono events, video quality as spatial information (SI) and temporal information, video block/blur/black/interlacing/crop/freeze detection, video and audio iterate frames, video frame duration stability, video GOP (group of picture) size (number of frames by GOP, and by frame type), video GOP frame size, by frame type, by GOP, by frame numbersignalimage: Signal image representation Draw an image from raw signal like audio wavformsnapshots: Image snapshots Extract image snapshots (significant and strip) from media filereport: HTML document report with file and signal stats, event detection, codecs, GOP stats...jsonreport: JSON document report with the same informations as html reportffprobexml: Media file headers on FFprobe XML
You can use several exports formats on one launch, like -f txt -f xml -f json.
NB: exports formats like XML or JSON can produce very large files, which may take time to make, if want to use all filters/analysis scopes (up to 4 MB for a file less than 1 minute of media). It's not a problem for Mediadeepa, but it can be for you!
Getting started
Dependencies needed for run Mediadeepa
- Java/JRE/JDK 21+
- FFmpeg/FFprobe v5+ (v7+ highly recommended)
Declared on OS (Windows/Linux/macOS) PATH.
Get Linux application packages
Download the last application release, as a Linux RPM or DEB package, or as an executable JAR (autonomous fat JAR file), downloaded directly from GitHub releases page, and build at each releases.
Install/update with
# DEB file on Debian/Ubuntu Linux distribs
sudo dpkg -i mediadeepa-0.1.0.deb
# RPM file on RHEL/CentOS Linux distribs
sudo rpm -U mediadeepa-0.1.0.rpm
Remove with sudo dpkg -r mediadeepa or rpm -e mediadeepa.
After, on Linux, run mediadeepa [parameters], and man mediadeepa for the internal doc man page.
Run simple JAR file
On Windows/macOS, just run java -jar mediadeepa-0.1.0.jar [options].
And simply run the application with java -jar mediadeepa-0.1.0.jar.
Mediadeepa contain embedded help, displayed with the -h parameter.
You can set the command line parameters with java -jar mediadeepa-0.1.0.jar [parameters].
Make a Java executable JAR file
You can build yourself a JAR, with Git and Maven.
Run on Linux/WSL/macOS, after setup Git and Maven:
git clone https://github.com/mediaexmachina/mediadeepa.git
cd mediadeepa
mvn install -DskipTests
Build jar will be founded on target directory as mediadeepa-0.1.0.jar
Examples
Process to export
Export to the current directory the analysis report for the file videofile.mov:
mediadeepa -i videofile.mov -f report -e .
Export to my Download directory the analysis result, as MS Excel and graphic files, the media file videofile.mov, only for audio and media container:
mediadeepa -i videofile.mov -c -f xlsx -f graphic -vn -e $HOME/Downloads
All available Export formats type are listed by:
mediadeepa -o
Import or Process to extract
Just:
mediadeepa -i videofile.mov --extract analysing-archive.zip
You can setup FFmpeg, like with import, like:
mediadeepa -i videofile.mov -c -an --extract analysing-archive.zip
Extracted (archive) ZIP file can be loaded simply by -i:
mediadeepa -i analysing-archive.zip -f report -f graphic -e .
Multiple Import or Process
Add -i options to works with multiple files, like:
mediadeepa -i analysing-archive.zip -i videofile.mov -i anotherfile.wav -f report -f graphic -e .
You can mix archive zip files and media files, but beware to not import with extract (zip to zip) or use single output file mode (--single-export).
Directory scan to input files
With the same restrictions as Multiple Import or Process, you can use a directory with -i parameter.
mediadeepa -i /some/directory -i /some/another/directory -f report -f graphic -e .
All non hidden founded files, not recursively (ignore the sub directories) will be used. You should use include/exclude parameter to manage the file selection criteria.
Use:
mediadeepa -i /some/directory --recursive --exclude-path never-this --include-ext ".mkv" -f report -f graphic -e .
To
- scan recursively
/some/directorydirectory - with the
/some/directory/never-this/*directory ignored - only for MKV files
More options are available.
Realities directory scan to input files
With the same options and restrictions as Directory scan to input files, just add --scan 10 to scan every 10 seconds all provided directories (simple -i files will be processed on application starts), like:
mediadeepa -i /some/directory --scan 10 -f report -f graphic -e .
Stop the scans with a key-press, or just with CTRL+C.
Load files to process from a text file
With the -il, as input list option:
mediadeepa -if my-medias.txt -f report -f graphic -e .
And the my-medias.txt file can just contain:
analysing-archive.zip
videofile.mov
anotherfile.wav
- Any space lines are ignored.
- Charset load respect the current OS session.
- You can use Windows and Linux new lines symbols (and you can mix them).
- You can accumulate multiple
-iand-iloptions, with the same limits as Multiple Import or Process. - Before starts the imports and processing, the application will check and throw an error if a file is missing (in
-i,-il, and in the lists itself).
You can read the FFmpeg filter documentation to know the behavior for each used filters, and the kind of returned values.
Command line options
Refer to the integrated command line help to get the full list.
Refer to FFmpeg documentation to have more details on the works of each filter, and on the expected values.
No option are mandatory ; all will be empty and let to the default values to FFmpeg.
General options
-h,--helpShow the usage help-v,--versionShow the application version-o,--optionsShow the avaliable options on this system--autocompleteShow the autocomplete bash script for this application-i,--inputFILE, can be used multiple times, Input (source media or Mediadeepa archive) file or full directory to work with-il,--input-listTEXT_FILE_LIST, can be used multiple times, Read input files from a text list--tempDIRECTORYTemp dir to use in the case of the needs to export to a temp file--verboseVerbose mode-q,--quietQuiet mode (don't log anyting, except errors)--logLOG_FILERedirect all log messages to text file--graphic-jpgExport to JPEG instead to PNG the produced graphic images
Specific options
Scan directory options
-r,--recursiveScan a directory and all its sub directory to work with--scanSECONDSTime, in seconds, between two regular scan of input directories, if applicable--include-extEXTENTION, can be used multiple times, Only search files with this extention, during directory scan--exclude-extEXTENTION, can be used multiple times, Ignore files with this extention, during directory scan--exclude-pathPATH, can be used multiple times, Ignore files founded under this directory, during directory scan--include-fileFILE_NAME, can be used multiple times, Only search files with this name (with willcards), during directory scan--include-dirDIRECTORY_NAME, can be used multiple times, Only search sub-directories with this name (with willcards), during directory scan--exclude-fileDIRECTORY_NAME, can be used multiple times, Ignore files with this name (with willcards), during directory scan--exclude-dirDIRECTORY_NAME, can be used multiple times, Ignore sub-directories with this name (with willcards), during directory scan--include-hiddenAllow hidded files (and dot files), during directory scan--include-linkAllow symbolic links, during directory scan
Process media file options
-c,--containerDo a container analysing (ffprobe streams)-tDURATIONDuration of input file to proces it See https://ffmpeg.org/ffmpeg-utils.html#time-duration-syntax-ssDURATIONSeek time in input file before to proces it See https://ffmpeg.org/ffmpeg-utils.html#time-duration-syntax-maxSECONDSMax time let to process a file-fo,--filter-onlyFILTER, can be used multiple times, Allow only this filter(s) to process (-o to get list)-fn,--filter-noFILTER, can be used multiple times, Not use this filter(s) to process (-o to get list)-mn,--media-noDisable media analysing (ffmpeg)-wfn,--wavform-noDisable wavform measuring (ffmpeg)-snn,--snapshot-noDisable image snapshot extraction (ffmpeg)
Media type exclusive
-an,--audio-no, required, Ignore all video filters-vn,--video-no, required, Ignore all audio filters
Internal filters parameters
--filter-ebur128-targetDBFS--filter-freeze-noisetoleranceDB--filter-freeze-durationSECONDS--filter-idet-intlTHRESHOLD_FLOAT--filter-idet-progTHRESHOLD_FLOAT--filter-idet-repTHRESHOLD_FLOAT--filter-idet-hlFRAMES--filter-crop-limitINT--filter-crop-roundINT--filter-crop-skipFRAMES--filter-crop-resetFRAMES--filter-crop-lowINT--filter-crop-highINT--filter-blur-lowTHRESHOLD_FLOAT--filter-blur-highTHRESHOLD_FLOAT--filter-blur-radiusPIXELS--filter-blur-block-pctPERCENT--filter-blur-block-widthPIXELS--filter-blur-block-heightPIXELS--filter-blur-planesINDEX--filter-block-period-minINT--filter-block-period-maxINT--filter-block-planesINDEX--filter-black-durationMILLISECONDS--filter-black-ratio-thTHRESHOLD_FLOAT--filter-black-thTHRESHOLD_FLOAT--filter-aphase-toleranceRATIO--filter-aphase-angleDEGREES--filter-aphase-durationMILLISECONDS--filter-silence-noiseDBFS--filter-silence-durationSECONDS
Output options
Extract to archive
--extractMEDIADEEPA_FILE, required, Extract all raw ffmpeg datas to a Mediadeepa archive file
Export to generated files
-f,--formatFORMAT_TYPE, can be used multiple times, Format to export datas-e,--exportDIRECTORYExport datas to this directory--export-base-filenameFILENAMEBase file name for exported data file(s)
Single export option
--single-export, required, Export only this file, as: "internal-file-name:outputfilename.ext" or "internal-file-name:-" to stdout
Limit the scope of analysis
By default, all analysis options and filters are activated in relation to your FFmpeg setup. Container analysis is still optional (via -c).
Not all options are necessarily useful for everyone and all the time (like crop detect), the processing of certain filters can be very resource intensive (like SITI), and/or produce a large amount of data.
You can list all active filters with the -o option, directly loaded from your current FFmpeg setup.
The description of each filter comes from the return of FFmpeg command.
And you can choose the analysis processing with these options:
--filter-only FILTERand--filter-no FILTER.--audio-no,--video-noand--media-no.--container
The -e parameter set the target export directory to put the produced files.
The --export-base-filename set a base name, used like BASENAME-export-format-internal-name.extension.
Single export option
With the help of --single-export option, you can choose and select an unique file to export, without the need to select an export format, or a directory.
The use of --single-export invalidate these options: -f/--format, -e/--export and --export-base-filename.
It can be used with a media or ZIP archive input file.
All filter options behaves the same way as full export: you should disable some analyzing options if you don't need it. Like -vn if you just want to export an audio related format.
Don't input (-i) more than one file.
Single export option is not compatible with french CSVs, either with multiple image snapshot%d.jpg.
Syntax
--single-export <internal-file-name>:<outputfilename.ext>
--single-export <internal-file-name>:-
With <internal-file-name>, the internal app file name "linked" to a export format. See below the full list.
With <outputfilename.ext>, the full path file to produce as result, or set - to send the result to std out.
The
-output option will silent log messages output in std out
Example:
--single-export audio-loudness:/home/me/lufs.png
Will produce an audio-loudness graphic file on /home/me/lufs.png file.
--single-export audio-loudness:-
Will produce and send the same file to std out, ready to be piped to another command.
For information,
graphicexport format files has no extension. By default, it export PNG files. Change this with--graphic-jpg.
Here the full available internal files that you can use (CSV FR format can't be selected):
Values separated by tabs in text files (txt)
about.txtaudio-ebur128-summary.txtaudio-ebur128.txtaudio-phase-meter.txtaudio-stats.txtcontainer-audio-consts.txtcontainer-audio-frames.txtcontainer-packets.txtcontainer-video-consts.txtcontainer-video-frames.txtcontainer-video-gop.txtevents.txtfilters.txtmedia-summary.txtvideo-block-detect.txtvideo-blur-detect.txtvideo-crop-detect.txtvideo-interlace-detect.txtvideo-siti-ITU-T_P-910.txtvideo-siti-stats-ITU-T_P-910.txt
Classic CSV files (csv)
about.csvaudio-ebur128-summary.csvaudio-ebur128.csvaudio-phase-meter.csvaudio-stats.csvcontainer-audio-consts.csvcontainer-audio-frames.csvcontainer-packets.csvcontainer-video-consts.csvcontainer-video-frames.csvcontainer-video-gop.csvevents.csvfilters.csvmedia-summary.csvvideo-block-detect.csvvideo-blur-detect.csvvideo-crop-detect.csvvideo-interlace-detect.csvvideo-siti-ITU-T_P-910.csvvideo-siti-stats-ITU-T_P-910.csv
French flavor CSV files (csvfr)
about.csvaudio-ebur128-summary.csvaudio-ebur128.csvaudio-phase-meter.csvaudio-stats.csvcontainer-audio-consts.csvcontainer-audio-frames.csvcontainer-packets.csvcontainer-video-consts.csvcontainer-video-frames.csvcontainer-video-gop.csvevents.csvfilters.csvmedia-summary.csvvideo-block-detect.csvvideo-blur-detect.csvvideo-crop-detect.csvvideo-interlace-detect.csvvideo-siti-ITU-T_P-910.csvvideo-siti-stats-ITU-T_P-910.csv
XML Document (xml)
media-datas.xml
JSON Document (json)
media-datas.json
XLSX Spreadsheet (xlsx)
media-datas.xlsx
SQLite database (sqlite)
media-datas.sqlite
Data graphical representation (graphic)
audio-bitrateaudio-dcoffsetaudio-dynamic-rangeaudio-entropyaudio-flatnessaudio-loudnessaudio-loundness-truepeakaudio-noise-flooraudio-peak-levelaudio-phaseaudio-rms-leveleventsvideo-bitratevideo-blockvideo-blurvideo-cropvideo-frame-durationvideo-gop-countvideo-gop-sizevideo-idetvideo-siti
Signal image representation (signalimage)
waveform.png
Image snapshots (snapshots)
snapshot%d.jpgsnapshot.jpg
HTML document report (report)
report.html
JSON document report (jsonreport)
report.json
Media file headers on FFprobe XML (ffprobexml)
ffprobe.xml
Internal variables options
It's possible to configure additional options to define internal application variables.
To setup a variable (internally, an injected Spring Boot configuration, Mediadeepa will follow Spring Boot behaviors), you have several options.
Use a YAML or Properties file
See some documentation, and this.
Prepare your application.yaml | application.property file with the wanted options, and inject it to the app like:
mediadeepa --spring.config.location=application.yaml -i videofile.mov -c -f xlsx [...]
Directly on command line
Simply with:
mediadeepa --mediadeepa.graphic-config.jpeg-compression-ratio=0.6 -i videofile.mov -c -f xlsx [...]
Available options
You can refer to this full list:
mediadeepa.add-source-ext-to-output-directories=false # boolean
mediadeepa.ffmpeg-exec-name=ffmpeg # String
mediadeepa.ffprobe-exec-name=ffprobe # String
mediadeepa.ffprobexml-file-name=ffprobe.xml # String
mediadeepa.graphic-config.a-bitrate-graphic-filename=audio-bitrate # String
mediadeepa.graphic-config.a-phase-graphic-filename=audio-phase # String
mediadeepa.graphic-config.block-graphic-filename=video-block # String
mediadeepa.graphic-config.blur-graphic-filename=video-blur # String
mediadeepa.graphic-config.crop-graphic-filename=video-crop # String
mediadeepa.graphic-config.dc-offset-graphic-filename=audio-dcoffset # String
mediadeepa.graphic-config.dynamic-range-graphic-filename=audio-dynamic-range # String
mediadeepa.graphic-config.entropy-graphic-filename=audio-entropy # String
mediadeepa.graphic-config.events-graphic-filename=events # String
mediadeepa.graphic-config.flatness-graphic-filename=audio-flatness # String
mediadeepa.graphic-config.gop-count-graphic-filename=video-gop-count # String
mediadeepa.graphic-config.gop-size-graphic-filename=video-gop-size # String
mediadeepa.graphic-config.image-size-full-size.height=1200.0 # double
mediadeepa.graphic-config.image-size-full-size.width=2000.0 # double
mediadeepa.graphic-config.image-size-half-size.height=600.0 # double
mediadeepa.graphic-config.image-size-half-size.width=2000.0 # double
mediadeepa.graphic-config.itet-graphic-filename=video-idet # String
mediadeepa.graphic-config.lufs-graphic-filename=audio-loudness # String
mediadeepa.graphic-config.lufs-t-p-k-graphic-filename=audio-loundness-truepeak # String
mediadeepa.graphic-config.noise-floor-graphic-filename=audio-noise-floor # String
mediadeepa.graphic-config.peak-level-graphic-filename=audio-peak-level # String
mediadeepa.graphic-config.rms-level-graphic-filename=audio-rms-level # String
mediadeepa.graphic-config.siti-graphic-filename=video-siti # String
mediadeepa.graphic-config.v-bitrate-graphic-filename=video-bitrate # String
mediadeepa.graphic-config.v-frame-duration-graphic-filename=video-frame-duration # String
mediadeepa.jpeg-compression-ratio=0.95 # float
mediadeepa.jsontable-file-name=media-datas.json # String
mediadeepa.logtofile-pattern=%d{ISO8601} %-5level %msg%n # String
mediadeepa.report-config.add-images=true # boolean
mediadeepa.report-config.display-image-size-width=1000 # int
mediadeepa.report-config.html-filename=report.html # String
mediadeepa.report-config.json-filename=report.json # String
mediadeepa.report-config.json-ident-output=true # boolean
mediadeepa.report-config.max-crop-events-display=20 # int
mediadeepa.scan-dir.depth-scan-directories=10 # int
mediadeepa.scan-dir.ignore-files=desktop.ini:.DS_Store:Thumbs.db # String
mediadeepa.scan-dir.min-fixed-state-time=500 # int
mediadeepa.scan-dir.retry-after-time-factor=10 # int
mediadeepa.silent-warn-mismatch-zip-archive-version=false # boolean
mediadeepa.snapshot-image-config.export-significant=true # boolean
mediadeepa.snapshot-image-config.search-best-frame-on-count=10 # int
mediadeepa.snapshot-image-config.significant-jpeg-filename=snapshot.jpg # String
mediadeepa.snapshot-image-config.strip-expected-count=8 # int
mediadeepa.snapshot-image-config.strip-jpeg-filename=snapshot%d.jpg # String
mediadeepa.sqllitetable-file-name=media-datas.sqlite # String
mediadeepa.wav-form-config.image-size.height=600.0 # double
mediadeepa.wav-form-config.image-size.width=2000.0 # double
mediadeepa.wav-form-config.png-filename=waveform.png # String
mediadeepa.xmltable-file-name=media-datas.xml # String
mediadeepa.xslxtable-file-name=media-datas.xlsx # String
mediadeepa.zipped-archive.command-line-json=commandline.json # String
mediadeepa.zipped-archive.container-xml=container.xml # String
mediadeepa.zipped-archive.ffmpeg-command-line-txt=ffmpeg-cmdline.txt # String
mediadeepa.zipped-archive.ffprobe-command-line-txt=ffprobe-cmdline.txt # String
mediadeepa.zipped-archive.ffprobe-xml=ffprobe.xml # String
mediadeepa.zipped-archive.filters-json=filters.json # String
mediadeepa.zipped-archive.image-snapshot-json=significant-image-snapshot.json # String
mediadeepa.zipped-archive.lavfi-txt-base=lavfi # String
mediadeepa.zipped-archive.measured-wav-json=waveform.json # String
mediadeepa.zipped-archive.significant-image-snapshot-jpg=significant-image-snapshot.jpg # String
mediadeepa.zipped-archive.source-name-txt=sourcename.txt # String
mediadeepa.zipped-archive.strip-image-snapshot-jpg=strip-image-snapshot.jpg # String
mediadeepa.zipped-archive.summary-txt=summary.txt # String
mediadeepa.zipped-archive.version-json=version.json # String
Logging
You can manage output logs with specific options, like --verbose, -q and --log.
This application use internally Logback. The actual and default configuration XML file can be found on source code in src/main/resources/logback.xml.
To inject a new logback configuration file, add in application command line:
-Dlogging.config="path/to/new/logback.xml"
For information, the use of --single-export option to - (std out) will cut all std out log messages, but you will stay able to send log messages to text file via --log option.
Search path binaries
Mediadeepa can search on several paths to found ffmpeg/ffmpeg.exe and ffprobe/ffprobe.exe (sorted by search order):
- directly declared on command line by
-Dexecfinder.searchdir=c:\path1;c:\path2\subpathon Windows or-Dexecfinder.searchdir=/path1:/path2/subpathon Posix - on
$HOMEdirectory - on
$HOME/bindirectory, if exists - on
$HOME/App/bindirectory, if exists - on any classpath directory declared, if exists
- on the global
PATHenvironment variable
Either on Linux/Posix and Windows.
You can inject other binary names (other than ffmpeg/ffprobe) with: mediadeepa.ffmpegExecName and mediadeepa.ffprobeExecName configuration keys. .exe on Windows will be added/removed as needed by the application.
In summary, if FFmpeg/FFprobe is runnable from anywhere on your host (PATH), you'll have nothing to do.
Application return
The application can produce several files, but return mostly processing status and log messages.
Return codes
0: Ok/done2: Error
Documentation, contributing and support
You can found some documentation:
- On the Mediadeepa website https://gh.mexm.media/mediadeepa
- On the project's README on GitHub.
- On the Mediadeepa command line interface.
- On the integrated app man page.
This documentation source is located on src/main/resources/doc/en directory.
Send bug reports on GitHub project page
- Help with the documentation.
- Propose pull requests.
- Or just take time to test the application and report the experience.
If you have any questions, feel free to reach out via any contact method listed on https://mexm.media.
![]()
![]()
End-to-end automatic tests
In the project source repository, you will found some tools to end-to-ends (e2e) automatic tests, in order to check the application behavior with real video files.
These tests are optional during the run of classical automatic tests, and only concerns dev. operations.
To run classical automatic tests, just run a mvn test.
To run e2e tests, you will need ffmpeg and bash:
- Create video tests files on
.demo-media-fileswithbash create-demo-files.bash(approx 230MB). - Optionally run
bash create-long-demo-file.bashto create a big test video file. - Next, just run
mvn test.
E2e tests take time. They will produce temp files in target directory (e2e* directories). A simple mvn clean wipe them, else the e2e scripts can reuse old generated files and don't loose some time.
E2e tests deeply checks all produced data from the application.
Releases
On each git tag, a GitHub Action will make a DEB and a RPM package on GitHub releases.
This Action use linux-springboot-packager to generate this files. Free feel to read this project documentation.
These packages are provided "as-it", as same for Mediadeepa. They are not signed.
Road-map
Some changes have been planned, like:
- Analyzing all audio streams, better MXF audio tracks and audio track management.
- Manage variable frame rate statistics (actually done, but need to be deeply checked to ensure the measure method is correct).
- Work on live streams, instead of just regular files.
- FFmpeg and FFprobe parallel executions.
- Content checking with automatic technical validation
And many others, I hope !
Auto-generated documentation
Bash-completion
The application provide a dynamic bash-completion script generated by:
java -jar target/mediadeepa-0.1.0.jar --autocomplete
Man page
An auto-generated man page can be produced by an internal option:
java -Dexportdocumentation.manpage="/full/path/to/file.man" -jar target/mediadeepa-0.1.0.jar
README page
Auto-generated by Mediadeepa, like the man page, and can be produced by the internal option:
java -Dexportdocumentation.readme="README.md" -jar target/mediadeepa-0.1.0.jar
All source text for documentation is either auto-generated by the internal application options and static markdown files in the src/main/resources/doc/en directory.
Project web page
Auto-generated by Mediadeepa, like the man and README pages, and can be produced by the internal option:
java -Dexportdocumentation.website="docs/index.html" -jar target/mediadeepa-0.1.0.jar
Same method to generate this file, like README/man files does.
Acknowledgments
Mediadeepa would never have been possible without the help of these magnificent and amazing OSS projects:
And the tech stack:
- Java 21
- Spring Boot 3
- Picocli 4
- My
prodlibandmedialibutility libs. - Maven (see
pom.xmlfor more information) - Open CSV
- Apache POI (poi-ooxml)
- SQLite JDBC
- Jackson
- jFreechart
- j2html
See THIRD-PARTY.txt file for more information on licenses and the full tech stack.